- Collect and prepare the data.
- Estimate the propensity scores.
- Match the participants using the estimated scores.
- Evaluate the covariates for an even spread across groups.
Hereof, why do we need propensity score?
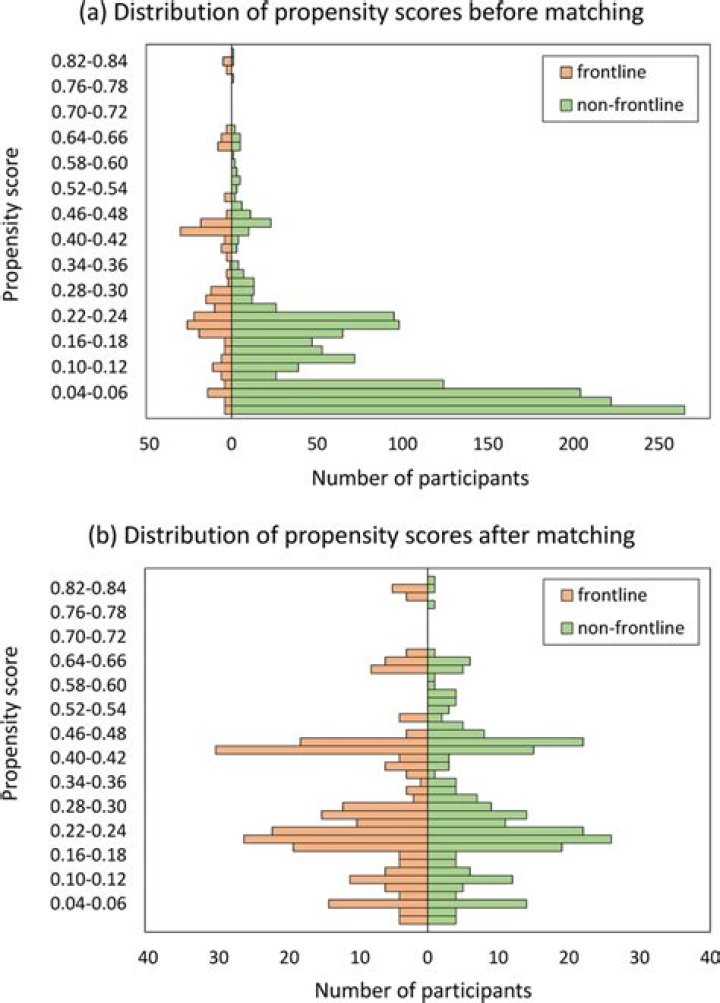
The application of the propensity score allows us to obtain a balanced dataset and a more precise estimate of gender differences in mortality of patients (study endpoint).
Likewise, what is a propensity score method? The propensity score is the probability of treatment assignment conditional on observed baseline characteristics. The propensity score allows one to design and analyze an observational (nonrandomized) study so that it mimics some of the particular characteristics of a randomized controlled trial.
Beside above, what is the purpose of propensity score matching?
Propensity score matching (PSM) is a quasi-experimental method in which the researcher uses statistical techniques to construct an artificial control group by matching each treated unit with a non-treated unit of similar characteristics. Using these matches, the researcher can estimate the impact of an intervention.
How do you get a propensity score?
Propensity scores are used to reduce confounding and thus include variables thought to be related to both treatment and outcome. To create a propensity score, a common first step is to use a logit or probit regression with treatment as the outcome variable and the potential confounders as explanatory variables.
Related Question Answers
Why not use propensity score matching?
We show that propensity score matching (PSM), an enormously popular method of preprocessing data for causal inference, often accomplishes the opposite of its intended goal --- thus increasing imbalance, inefficiency, model dependence, and bias.What is propensity model?
A propensity model is a statistical scorecard that is used to predict the behaviour of your customer or prospect base. Propensity models are often used to identify those most likely to respond to an offer, or to focus retention activity on those most likely to churn.What is propensity analysis?
A propensity analysis is a statistical approach that attempts to reduce selection bias and known confounding in an observational study. Propensity scores estimate the probability that an individual would have received a particular treatment based on observed baseline characteristics.Why do we do matching?
Matching is a technique used to avoid confounding in a study design. Because in a matched case-control study case and control group become too similar not only in the distribution of the confounder but also in the distribution of the exposure, one finds a lower effect estimate (odds ratio closer to 1).How does propensity matching work?
Propensity score matching (PSM) is a quasi-experimental method in which the researcher uses statistical techniques to construct an artificial control group by matching each treated unit with a non-treated unit of similar characteristics. Using these matches, the researcher can estimate the impact of an intervention.What is propensity score stratification?
Propensity stratification divides the observations into strata that have similar propensity scores, with the objective of balancing the observed variables between treated and control units within each stratum. The treatment effect can then be estimated by combining stratum-specific estimates of treatment effect.What is propensity value?
1 – Propensity values describing physical-chemical properties of residues at the interface as estimated in (Nagi and Braun 2007). A value ≥ 1 suggests that a residue most likely belongs to an interface rather than outside of it.Is propensity score matching quasi experimental design?
Although propensity score matching continues to be demonstrated as a superior quasi-experimental method in the literature, it remains underutilized in educational research.What is matching method?
From Wikipedia, the free encyclopedia. Matching is a statistical technique which is used to evaluate the effect of a treatment by comparing the treated and the non-treated units in an observational study or quasi-experiment (i.e. when the treatment is not randomly assigned).What is Mahalanobis matching?
Affinely invariant matching methods, such as propensity score or Mahalanobis metric matching, are those that yield the same matches following an affine (linear) transformation of the data. Matching in this general setting is shown to be Equal Percent Bias Reducing (EPBR; Rubin, 1976b).What is coarsened exact matching?
“Coarsened exact matching” (CEM) is a design strategy that has been shown to produce good covariate balance between exposure groups and, thus, to reduce the impact of confounding in observational causal inference (1, 2).What is kernel matching?
With kernel matching, the closer the treated and untreated observations are based on the propensity score, the larger weight is given to the untreated observation. Thus, the more "similar" the untreated observations are to the treated observations, the more weight they are given.What is link propensity?
Link Propensity - A score from 0 to 1 indicating the likelihood of the target root domain to link out to other root domains. This is currently calculated as the ratio. Links from the same root domain as the target do not contribute to this count.How do you match propensity scores in Excel?
Setting up a propensity score matching. First, open the downloaded file with Excel and activate XLSTAT. Once XLSTAT is activated, select the XLSTAT / Advanced features / Survival analysis / Propensity score matching (see below). Once you have clicked on the button, the dialog box appears.What is Unconfoundedness assumption?
The unconfoundedness assumption says loosely that all the variables affecting both the treatment T and the outcome Y are observed (we call them covariates) and can be controlled for. Abadie [5] and Frölich [6] extended these results to the situation where the observed covariates are related to the instrument.What does covariate mean in statistics?
In general terms, covariates are characteristics (excluding the actual treatment) of the participants in an experiment. If you collect data on characteristics before you run an experiment, you could use that data to see how your treatment affects different groups or populations.What variables go into propensity score?
Baseline confounders could include age, gender, history of MI, previous drug exposures, and various comorbid conditions. A propensity score is the conditional probability that a subject receives a treatment or exposure under study given all measured confounders, i.e., Pr[A = 1|X1, X2, . . . , Xp].How does propensity score match in R?
- Estimate the propensity score (the probability of being Treated given a set of pre-treatment covariates).
- Examine the region of common support.
- Choose and execute a matching algorithm.
- Examine covariate balance after matching.
- Estimate treatment effects.
What is caliper in propensity score matching?
A caliper which means the maximum tolerated difference between matched subjects in a "non-perfect" matching intention is frequently set at 0.2 standard deviation as the default such as used in the PS Matching SPSS R-extension utilitiy.What is propensity score weighting?
Propensity score weighting is one of the techniques used in controlling for selection biases in non- experimental studies. Propensity scores can be used as weights to account for selection assignment differences between treatment and comparison groups.What is Caliper matching?
Caliper matching ( caliper )Any units for which there are no available matches within the caliper are dropped from the matched sample. Calipers ensure paired units are close to each other on the calipered covariates, which can ensure good balance in the matched sample.
How do you do a propensity model?
Here's the step-by-step process:- Select your features with a group of domain experts.
- After choosing linear or logistic regression, construct your model.
- Train your model using a data set and calculate your propensity scores.
- Use experimentation to verify the accuracy of your propensity scores.




