Accordingly, how do you make a Huffman tree?
Steps to build Huffman Tree
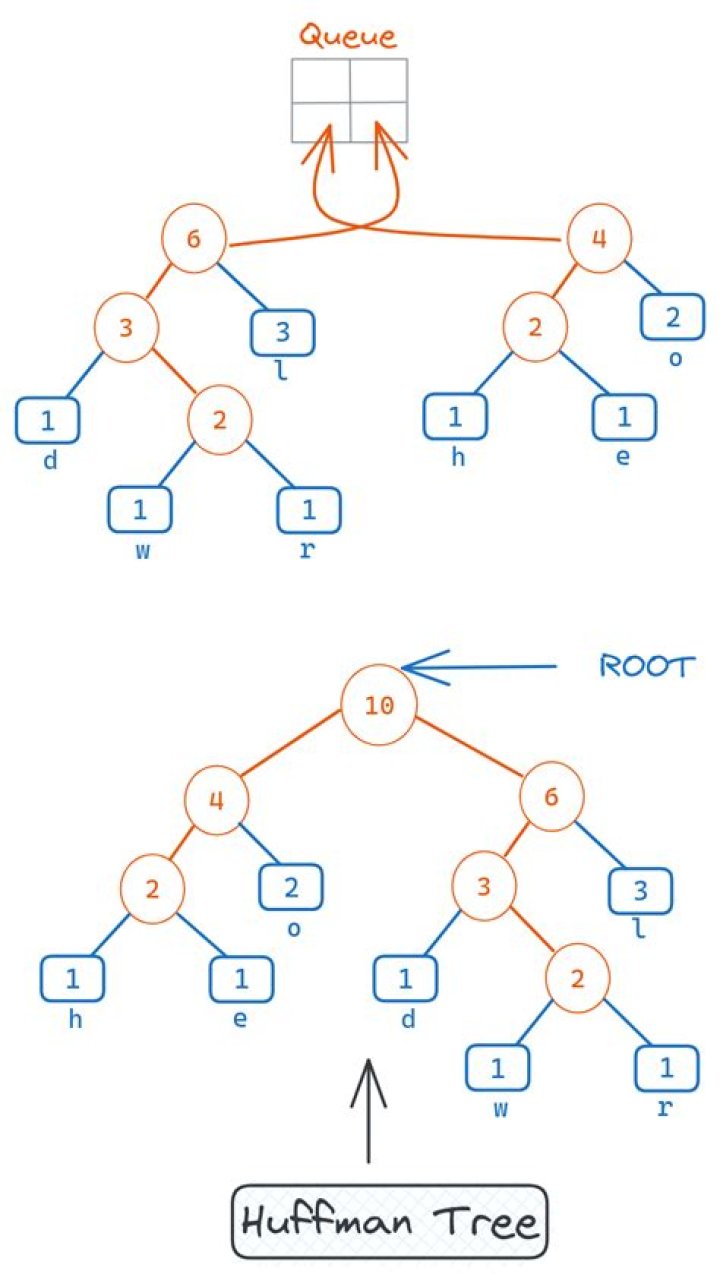
Extract two nodes with the minimum frequency from the min heap. Create a new internal node with a frequency equal to the sum of the two nodes frequencies. Make the first extracted node as its left child and the other extracted node as its right child. Add this node to the min heap.
Beside above, what is Huffman encoding in data structure? Huffman coding is a lossless data compression algorithm. In this algorithm, a variable-length code is assigned to input different characters. The code length is related to how frequently characters are used. Most frequent characters have the smallest codes and longer codes for least frequent characters.
Regarding this, which tree is used in Huffman coding?
The Huffman code for each letter is derived from a full binary tree called the Huffman coding tree, or simply the Huffman tree. Each leaf of the Huffman tree corresponds to a letter, and we define the weight of the leaf node to be the weight (frequency) of its associated letter.
Which approach is followed in constructing a Huffman tree?
If the symbols are sorted by probability, there is a linear-time (O(n)) method to create a Huffman tree using two queues, the first one containing the initial weights (along with pointers to the associated leaves), and combined weights (along with pointers to the trees) being put in the back of the second queue.
Related Question Answers
How does Huffman algorithm work?
Huffman coding uses a greedy algorithm to build a prefix tree that optimizes the encoding scheme so that the most frequently used symbols have the shortest encoding. The prefix tree describing the encoding ensures that the code for any particular symbol is never a prefix of the bit string representing any other symbol.How is Huffman code calculated?
Huffman code is obtained from the Huffman tree. Huffman code is a = 000, b = 001, c = 010, d = 011, e = 1. This is the optimum (minimum-cost) prefix code for this distribution. Given an alphabet A with frequency distribution {f(a) : a ∈ A}.What is Huffman coding in image processing?
Huffman coding is a lossless data compression technique. Huffman coding is based on the frequency of occurrence of a data item i.e. pixel in images. The technique is to use a lower number of bits to encode the data in to binary codes that occurs more frequently. It is used in JPEG files.What is Huffman decoding?
Huffman coding assigns variable length codewords to fixed length input characters based on their frequencies. To decode the encoded string, follow the zeros and ones to a leaf and return the character there. You are given pointer to the root of the Huffman tree and a binary coded string to decode.Which is the best way to solve Huffman codes?
Explanation: Greedy algorithm is the best approach for solving the Huffman codes problem since it greedily searches for an optimal solution.Why is Huffman coding optimal?
Answer (1 of 2): Huffman code is optimum because: 1. It reduce the number of unused codewords from the terminals of the… “In an optimum code, symbols that occur more frequently (have a higher probability of occurrence) will have shorter codewords than symbols that occur less frequently.â€How is Huffman coding used to compress data?
Huffman coding is a form of lossless compression which makes files smaller using the frequency with which characters appear in a message. This works particularly well when characters appear multiple times in a string as these can then be represented using fewer bits . This reduces the overall size of a file.What is binary tree data structure?
What is Binary Tree Data Structure? A binary tree is a tree-type non-linear data structure with a maximum of two children for each parent. Every node in a binary tree has a left and right reference along with the data element. The node at the top of the hierarchy of a tree is called the root node.What is binary search tree data structure?
In computer science, a binary search tree (BST), also called an ordered or sorted binary tree, is a rooted binary tree data structure whose internal nodes each store a key greater than all the keys in the node's left subtree and less than those in its right subtree.What is Huffman encoding scheme how it is beneficial in generating codes for alphabetic data set?
It is a lossless data compressing technique generating variable length codes for different symbols. It is based on greedy approach which considers frequency/probability of alphabets for generating codes. It has complexity of nlogn where n is the number of unique characters.What are the basic principles of Huffman coding?
Huffman coding is based on the frequency of occurance of a data item (pixel in images). The principle is to use a lower number of bits to encode the data that occurs more frequently. Codes are stored in a Code Book which may be constructed for each image or a set of images.What is the use of Huffman tree explain with suitable example?
Huffman coding is used in JPEG compression. The key idea behind Huffman coding is to encode the most common characters using shorter strings of bits than those used for less common source characters. It works by creating a binary tree stored in an array.How do you move through Huffman tree for encoding?
To find character corresponding to current bits, we use following simple steps.- We start from root and do following until a leaf is found.
- If current bit is 0, we move to left node of the tree.
- If the bit is 1, we move to right node of the tree.
How many bits may be required for encoding the message Mississippi with using Huffman coding?
Consider, for example, a file containing the single string, “Mississippiâ€, with no control characters signaling the end of the line. If we were to use one byte for each character, as UTF-8 would do, we would need 11 bytes (or 88 bits). However, we could encode the characters in binary as follows: M: 100.Which of the following is true about Huffman coding?
Which of the following is true about Huffman Coding. Explanation: Huffman coding is a lossless data compression algorithm. The codes assigned to input characters are Prefix Codes, means the codes are assigned in such a way that the code assigned to one character is not prefix of code assigned to any other character.What is AVL tree in data structure?
(data structure) Definition: A balanced binary search tree where the height of the two subtrees (children) of a node differs by at most one. Look-up, insertion, and deletion are O(log n), where n is the number of nodes in the tree.Where is Huffman coding used?
Huffman is widely used in all the mainstream compression formats that you might encounter - from GZIP, PKZIP (winzip etc) and BZIP2, to image formats such as JPEG and PNG.How is Huffman coding implemented?
There are three steps in creating the table:- Count the number of times every character occurs. Use these counts to create an initial forest of one-node trees.
- Use the greedy Huffman algorithm to build a single tree.
- Follow every root-to-leaf path creating a table of bit sequence encodings for every character/leaf.