Subsequently, one may also ask, what are data preprocessing methods?
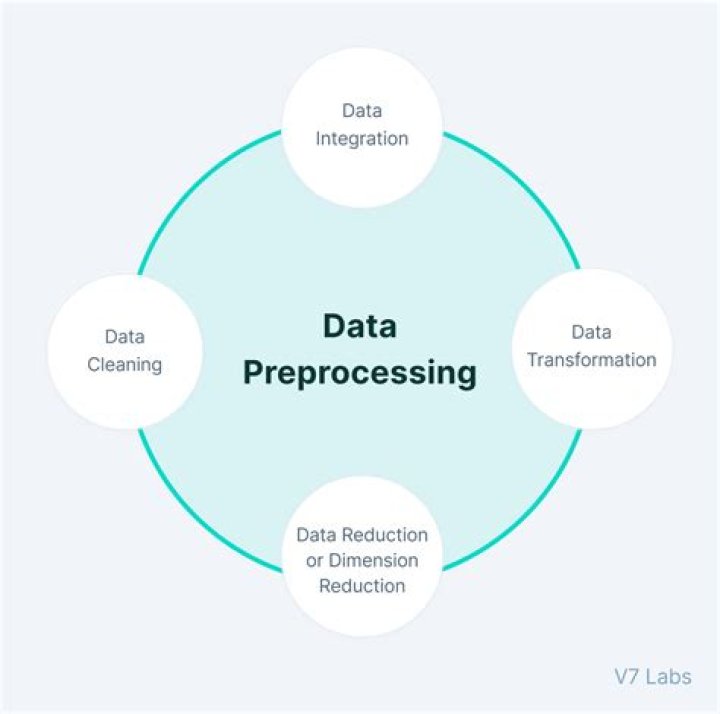
There are four methods of Data Preprocessing which are explained by A. Sivakumar and R. Gunasundari in their journal. They are Data Cleaning/Cleansing, Data Integration, Data Transformation, and Data Reduction.
Also Know, what is data preprocessing in data mining ppt? Major Tasks in Data Preprocessing • Data cleaning – Fill in missing values, smooth noisy data, identify or remove outliers, and resolve inconsistencies • Data integration – Integration of multiple databases, data cubes, or files • Data transformation – Normalization and aggregation • Data reduction – Obtains reduced
Herein, what is data preprocessing and why it is important?
Data preprocessing is an important step to prepare the data to form a QSPR model. Data cleaning and transformation are methods used to remove outliers and standardize the data so that they take a form that can be easily used to create a model.
Why do we need to preprocess data?
Data preprocessing is crucial in any data mining process as they directly impact success rate of the project. Data is said to be unclean if it is missing attribute, attribute values, contain noise or outliers and duplicate or wrong data. Presence of any of these will degrade quality of the results.
Related Question Answers
What is data preprocessing with example?
Data preprocessing involves transforming raw data to well-formed data sets so that data mining analytics can be applied. Raw data is often incomplete and has inconsistent formatting. The adequacy or inadequacy of data preparation has a direct correlation with the success of any project that involve data analyics.What is data preprocessing Tutorialspoint?
Advertisements. In the real world, we usually come across lots of raw data which is not fit to be readily processed by machine learning algorithms. We need to preprocess the raw data before it is fed into various machine learning algorithms.What is meaning of preprocessing?
A preliminary processing of data in order to prepare it for the primary processing or for further analysis. For example, extracting data from a larger set, filtering it for various reasons and combining sets of data could be preprocessing steps.What is a data preprocessing process give good examples for various types of data preprocessing process?
Data preparation and filtering steps can take considerable amount of processing time. Examples of data preprocessing include cleaning, instance selection, normalization, one hot encoding, transformation, feature extraction and selection, etc. The product of data preprocessing is the final training set.What are the main data preprocessing steps list and explain their importance in Analytics?
Phases in data preprocessing.Data preprocessing can be termed as a unique technique used in mining data that enhance the transformation of raw data to an efficient and useful data. There are three main phases in this process. They include; data consolidation, data cleaning, data transformation, and data reduction.
What is preprocessing in NLP?
In NLP, text preprocessing is the first step in the process of building a model. The various text preprocessing steps are: Tokenization. Lower casing. Stop words removal.What is meant by data preprocessing in machine learning?
Data preprocessing is a process of preparing the raw data and making it suitable for a machine learning model. It is the first and crucial step while creating a machine learning model. And while doing any operation with data, it is mandatory to clean it and put in a formatted way.Which of the following activities are performed as a part of data preprocessing?
Activities performed as part of data pre-processing are: Data Cleaning - Data is cleansed through methods like easing the noisy data, filling in missing values, or fixing the discrepancies in the data.What is data integration and transformation in data mining?
Data Integration is a data preprocessing technique that involves combining data from multiple heterogeneous data sources into a coherent data store and provide a unified view of the data. These sources may include multiple data cubes, databases, or flat files.How does machine learning preprocess data?
There are seven significant steps in data preprocessing in Machine Learning:- Acquire the dataset.
- Import all the crucial libraries.
- Import the dataset.
- Identifying and handling the missing values.
- Encoding the categorical data.
- Splitting the dataset.
- Feature scaling.