Similarly, why GRU is better than Lstm?
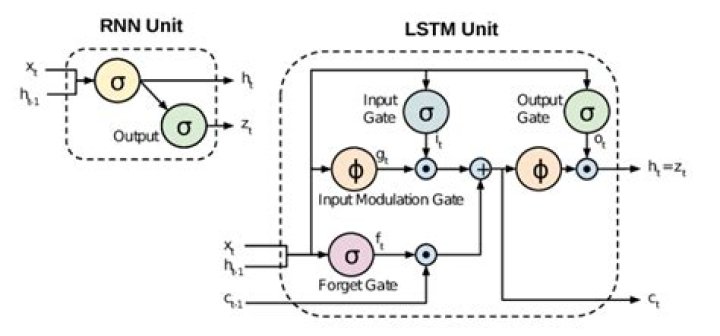
GRU use less training parameters and therefore use less memory, execute faster and train faster than LSTM's whereas LSTM is more accurate on dataset using longer sequence. In short, if sequence is large or accuracy is very critical, please go for LSTM whereas for less memory consumption and faster operation go for GRU.
Additionally, why do we use Tanh in Lstm? The output from tanh can be positive or negative, allowing for increases and decreases in the state. That's why tanh is used to determine candidate values to get added to the internal state. The GRU cousin of the LSTM doesn't have a second tanh, so in a sense the second one is not necessary.
Similarly, why is CNN better than RNN?
It is suitable for spatial data such as images. RNN is suitable for temporal data, also called sequential data. CNN is considered to be more powerful than RNN. RNN unlike feed forward neural networks - can use their internal memory to process arbitrary sequences of inputs.
Why do we use Lstm?
An LSTM allows the preservation of gradients. The memory cell remembers the first input as long as the forget gate is open and the input gate is closed. LSTM is basically considered to avoid the problem of vanishing gradient in RNN. An LSTM allows the preservation of gradients.
Related Question Answers
Is Lstm deep learning?
Long short-term memory (LSTM) is an artificial recurrent neural network (RNN) architecture used in the field of deep learning. LSTM networks are well-suited to classifying, processing and making predictions based on time series data, since there can be lags of unknown duration between important events in a time series.Is Gru faster than Lstm?
GRU use less training parameters and therefore use less memory, execute faster and train faster than LSTM's whereas LSTM is more accurate on dataset using longer sequence.Which is better Lstm or GRU?
GRU use less training parameters and therefore use less memory, execute faster and train faster than LSTM's whereas LSTM is more accurate on dataset using longer sequence. In short, if sequence is large or accuracy is very critical, please go for LSTM whereas for less memory consumption and faster operation go for GRU.How is Lstm trained?
The Long Short-Term Memory network, or LSTM network, is a recurrent neural network that is trained using Backpropagation Through Time and overcomes the vanishing gradient problem.Where is Lstm used?
LSTM is a good choice for such sequences which have long term dependencies in it. Recurrent networks, of which LSTM is one of the most successful, are generally useful when you're dealing with a time series, but there are other applications as well.Who invented Lstm?
Long short-term memory (LSTM) networks were discovered by Hochreiter and Schmidhuber in 1997 and set accuracy records in multiple applications domains. Around 2007, LSTM started to revolutionize speech recognition, outperforming traditional models in certain speech applications.What is RNN in deep learning?
A recurrent neural network (RNN) is a class of artificial neural networks where connections between nodes form a directed graph along a temporal sequence. This allows it to exhibit temporal dynamic behavior.Is Lstm good for time series?
Yes, LSTM Artificial Neural Networks , like any other Recurrent Neural Networks (RNNs) can be used for Time Series Forecasting. They are designed for Sequence Prediction problems and time-series forecasting nicely fits into the same class of problems.Which neural network is best?
Top 10 Neural Network Architectures You Need to Know- 1 — Perceptrons.
- 2 — Convolutional Neural Networks.
- 3 — Recurrent Neural Networks.
- 4 — Long / Short Term Memory.
- 5 — Gated Recurrent Unit.
- 6 — Hopfield Network.
- 7 — Boltzmann Machine.
- 8 — Deep Belief Networks.
Is CNN better than RNN?
RNN is suitable for temporal data, also called sequential data. CNN is considered to be more powerful than RNN. RNN unlike feed forward neural networks - can use their internal memory to process arbitrary sequences of inputs. CNNs use connectivity pattern between the neurons.Why is CNN better?
The main advantage of CNN compared to its predecessors is that it automatically detects the important features without any human supervision. ConvNets are more powerful than machine learning algorithms and are also computationally efficient.Is CNN a algorithm?
A Convolutional Neural Network (ConvNet/CNN) is a Deep Learning algorithm which can take in an input image, assign importance (learnable weights and biases) to various aspects/objects in the image and be able to differentiate one from the other.Is RNN supervised learning?
The entire deep learning (There are some unsupervised learning algorithms as well. But they are not much used and not popular as well. ) is based on supervised learning approach. So, yes CNN and RNN or even a simple neural network is supervised learning algorithms.What is the C in CNN?
Cable News Network is a U.S. cable news channel founded in 1980 by American media mogul Ted Turner.Why RNN is used for machine translation?
Why is an RNN (Recurrent Neural Network) used for machine translation, say translating English to French? (Check all that apply.) It is strictly more powerful than a Convolutional Neural Network (CNN). It is applicable when the input/output is a sequence (e.g., a sequence of words).What is hidden layer in CNN?
Hidden layers, simply put, are layers of mathematical functions each designed to produce an output specific to an intended result. Hidden layers allow for the function of a neural network to be broken down into specific transformations of the data. Each hidden layer function is specialized to produce a defined output.What is pooling in CNN?
Pooling Layers A pooling layer is another building block of a CNN. Pooling. Its function is to progressively reduce the spatial size of the representation to reduce the amount of parameters and computation in the network. Pooling layer operates on each feature map independently.Why is ReLU not used in RNN?
ReLU generally not used in RNN because they can have very large outputs so they might be expected to be far more likely to explode than units that have bounded values.How do you solve a vanishing gradient problem?
One of the newest and most effective ways to resolve the vanishing gradient problem is with residual neural networks, or ResNets (not to be confused with recurrent neural networks). It was noted prior to ResNets that a deeper network would actually have higher training error than the shallow network.What is a Tanh function?
The tanh function, a.k.a. hyperbolic tangent function, is a rescaling of the logistic sigmoid, such that its outputs range from -1 to 1. (There's horizontal stretching as well.) tanh(x)=2g(2x)−1.How can I improve my Lstm?
Network Structure- Gated Recurrent Unit. GRU (Cho14) alternative memory cell design to LSTM.
- Layer normalization. Adding layer normalization (Ba16) to all linear mappings of the recurrent network speeds up learning and often improves final performance.
- Feed-forward layers first.
- Stacked recurrent networks.